

新闻资讯
拥抱变化,赋能产业互联时代
拥抱新时代!AIGC
2023-08-01
要问2023年最火的是什么,那必然是由OpenAI旗下的ChatGPT掀起的关于生成式AI(artificial intelligent generation content,AIGC)的热潮。在讲述AIGC之前我们先来看看人工智能发展史,如下图1所示,人工智能技术上个世纪就开始发展,理论算法其实已经在上个世纪基本构筑完成,直到21世纪才爆发出属于其的耀眼光芒,在图像、语音、自然语言处理方面都有很大的应用,其中一个很大的原因在于硬件算力的支持,没错就是显卡带来的改变,甚至可以直接说是NVIDIA显卡带来的改变。
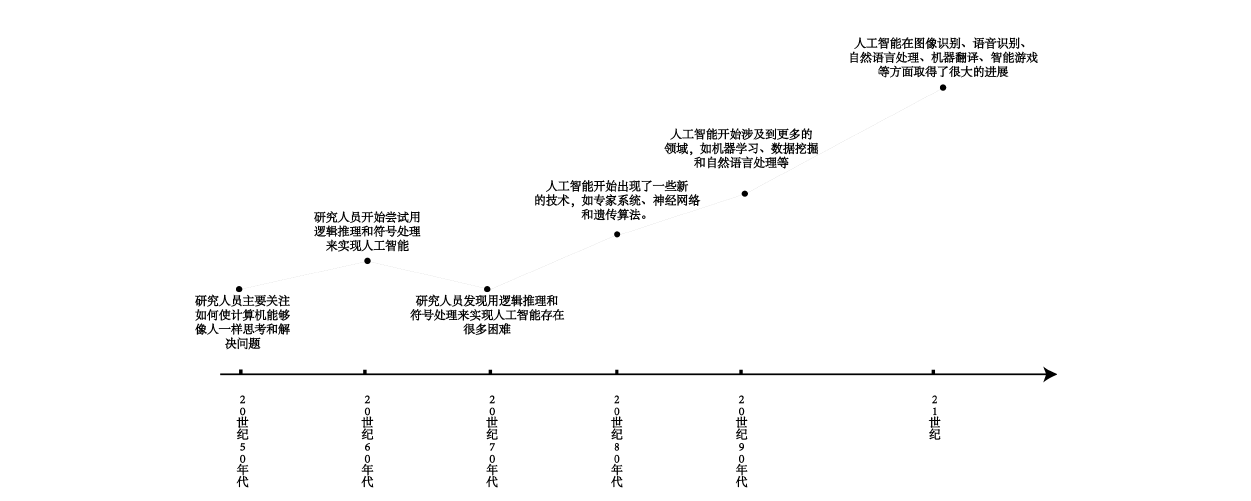
图1 人工智能发展史
人工智能自从2012年的深度学习浪潮开始不过11年就给人们带来许许多多的震撼,让我们把时间拨回2012年看看当时发生了什么事,2012年深度学习奠基作AlexNet横空出世,就像命运的齿轮开始转动一般,下图2是截选的改文章的一部分。从下图中可以知道AlexNet是一个在ImageNet分类比赛中的深度卷积神经网络,并且在当年以top-5误差率15.3%中获得了冠军,而当时获得第二名的传统机器学习top-5误差率为26.2%,可谓是一脚踹翻了传统机器学习,把世界带入了深度学习的新时代,因此该文章的第三位作者Geoffrey E. Hinton被称为深度学习之父,也是图灵奖的获得者,另外两名作者Alex Krizhevsky和Ilya Sutskever是其学生,值得一提的是Ilya Sutskever正是现如今如日中天OpenAI的首席科学家,知道什么叫师门传承了吧。

图2 AlexNet
AlexNet首次使用2块GPU进行深度学习训练,就是下图3这块CUDA数只有512个的GTX580,显存只有1536MB,FP32算力只有1.581TFLOPS,训练模型的时候还需要对模型进行切割,但就在这样的情况下还是取得了非凡的效果,因此人们才发现NVIDIA的显卡真的适合大规模的并行计算,深度学习真是yyds。NVIDIA也在以后的深度学习发展中占据了重要地位,随着显卡的不断迭代最新的4090显卡CUDA数已有16384个,显存为24GB,FP32算力值更是达到了82.58TFLOPS,两者就像是双螺旋结构互助成长,密不可分。NVIDIA在人工智能的硬件算力提供这一块占据了绝对领域,不可撼动,护城河深不见底。

图3 RTX580
人工智能的领域主要可分为两个部分,计算机视觉(Computer Vision,CV)和自然语言处理(Natural Language Processing,NLP),每个部分下面又可以细分为几个子任务,今年大火的GPT4属于NLP领域,而像Midjourney和Stable Diffusion这样的属于CV领域的图像生成部分,因为他们能够生成图片或文字内容,因此又被统称为生成式AI。
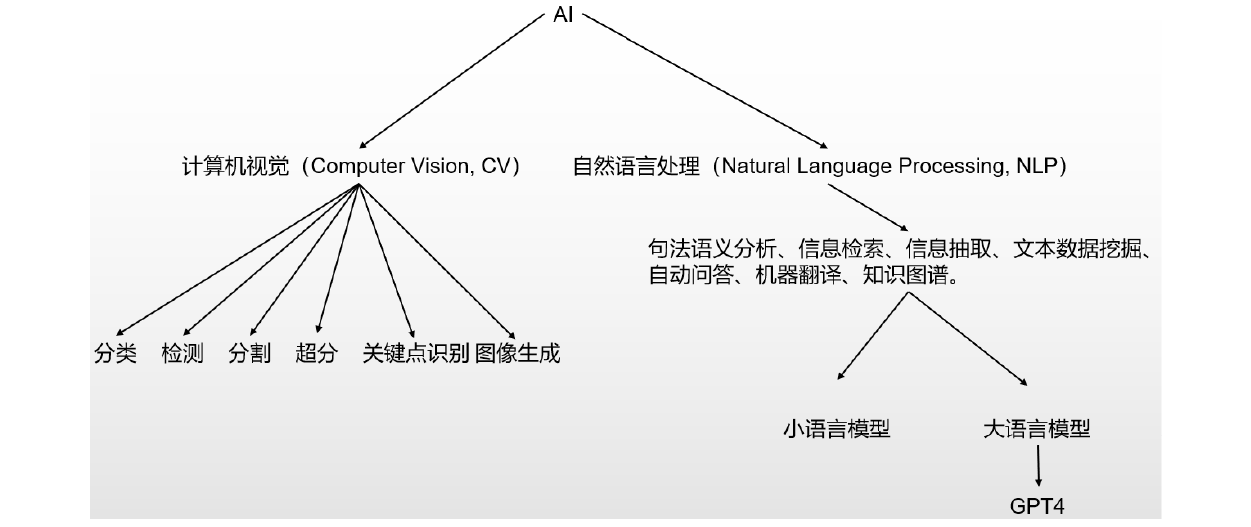
图4 AI任务分类
下图5是OpenAI发展的一个时间线,为大家把其中的爱恨情仇理清楚,2015年马斯克为了抗衡谷歌的人工智能领域,和阿尔曼等人联合创办了人工智能研究组织OpenAI,并宣称投资10亿美金用其发展,顾名思义这是一个开源的非盈利性组织。但在其前期发展中并有取得一些卓越型成功,让马斯克觉得有违初衷在AI领域制衡不了谷歌,因此马斯克就想独揽大权,重新规划发展,但是在董事会投票过程中以失败告终,因此马斯克愤而退出了OpenAI,并停止捐赠资金,这时候10亿美金实际上才捐赠了1亿美金。因此马斯克走后一年,OpenAI账上的资金就快要花完了,中间发布了GPT-1和GPT-2两个大语言模型,但是学术界认可度很一般,远低于谷歌同类型的Transformer,因此这个开源性质的组织被迫于2019年2月宣布成为盈利性实体,然后新大佬微软为其注资,这里提到一点微软至今还未收购OpenAI,只是为其投入资金,OpenAI的所有产品提供其使用。之后在2020年又推出了没什么用的GPT-3,直到2022年11月30日推出了震撼世人的ChatGPT聊天机器人,当时模型使用的GPT-3.5版本,自从微软注资已经过去3年多时间了,真是默默发展一朝惊人,而后又在2023年3月15日发布了GPT-4模型,远超同时代的其他同行,甚至连人工智能老大、行业一哥谷歌都招架不住。

图5 OpenAI发展脉络时间线
如果时间重来一次,马斯克没有退出OpenAI,那后续微软就不会介入,OpenAI还能有如今的成就吗,结论大概率是否定的。为什么微软是其成功的必要条件?如下图7所示,想要发展人工智能,简单来说就是训练出一个性能优异的AI模型需要具备三个条件,数据集、算力平台和底层核心代码。AI模型的精度和数据样本、算法的复杂度呈正相关的,而大量用来训练的数据样本以及复杂的算法对于硬件算力又有极高的要求。那么回过头来说,复杂算法这一块对于OpenAI来说是问题不大的,因为人家首席科学家就是师从深度学习之父的Ilya Sutskever;算力平台这一块微软云计算平台Azure为其提供海量算力;数据集方面微软更是能为其提供优质的数据,微软的bing浏览器这么多年存下的数据,更不用说其拥有的全球开源社区GitHub中的海量数据了。因此在微软的加持下,成功的公式已经成立,所有的困难也被清除。从这里回看国内的公司,他们面临的困难也是这三个,百度是目前唯一家有希望成功的公司,这也是人家敢开发布会的原因,因为数据集以及算力平台这一块百度是不缺的,但是底层核心代码这一块确实是掣肘国内发展的主要原因,因为大家已经习惯了使用人家的开源代码,最多拿别人开源的开源代码重构一遍,但是想从底层往上重建出一个大语言模型,缺少这样的核心人员,所以国内想在两三年中出现一个能媲美GPT-3.5的模型属实很难,其实质上就是模型精度不够,还实现不了从人工智障到人工智能的转变。

图7 人工智能发展所面临的困难